Crowd auralisations at DTU Science-park cafeteria
In this application, some of the Audio Effects in ODEON (like Change duration and Phase vocoder) are employed to create variations of two speech signals in order to construct a crowd of 30 sources around a receiver. The process starts by creating two sets of populations: One with 15 variations of single male speech signal and one with 15 variations of single female speech signal. The male speech signal is a 10 sec long excerpt from the ’Definition of Decibels’ (in English) written and performed by Mario Alfredo M. Sandoval, while the female speech signal is a 12.5 seclong excerpt from ’Aninha e suas pedras’ by Cora Coralina(in Brazilian Portuguese), performed by Caroline Gaudeoso.
On top of these 30 variations, we apply a speech signal in focus at a particular source location, near the receiver. The speech in focus is an excerpt from the literary folktale The Emperor’s New Clothes by Hans Christian Andersen. The excerpt is performed by C. L. Christensen.
The whole application is described in detail in the following paper:
C. L. Christensen, G. Koutsouris, A. Richard and J. H. Rindel, “Audio effects for multi-source auralisations”, I3DA International Conference, Virtual, 2021 (upcoming).
Input Speech Signals
Processed signals
Both the male ’Definition of Decibels’ and the female ’Aninha e suas pedras’ signals are processed through a chain of three audio effects: Phase Vocoder, Change Duration and Amplitude Modulation. Each process delivers 15 variations of each signal, which have differences in pitch and speed, as well as random pauses and repetitions. However, all variations end up having strictly the same duration of 1 min. Below four of these variations (two for each signal) are presented.
An interesting observation is that many of these files sound rather artificial when listening to them separately. However, despite this artificial impression, the result of the mixed files still sounds realistic enough (see below in ‘Crowd auralisations’).



Photos of the cafeteria.
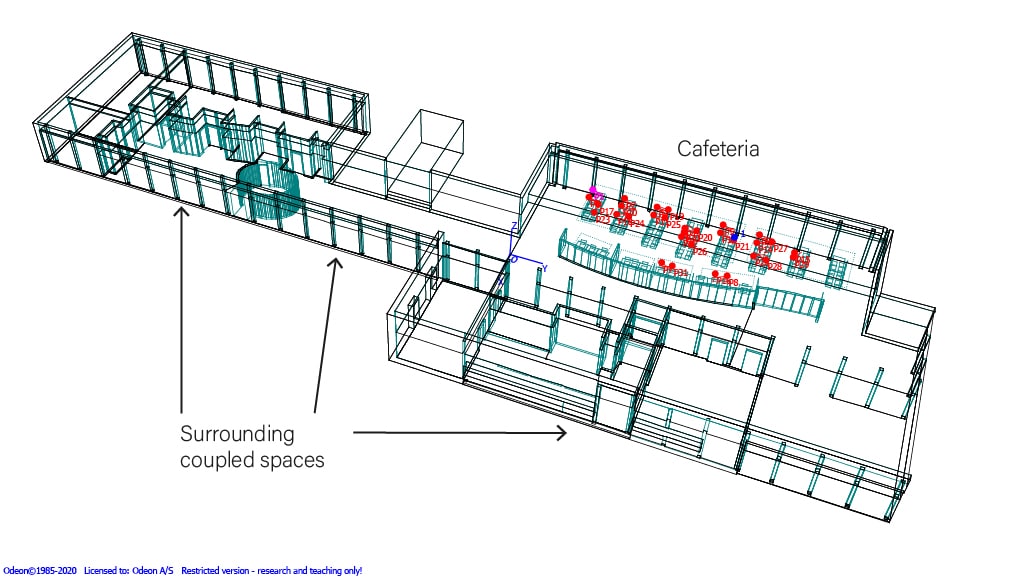
Wireframe of the cafeteria and the surrounding coupled spaces. The 30+1 sources and one receiver are placed on the right side and marked with red and blue colour, respectively.
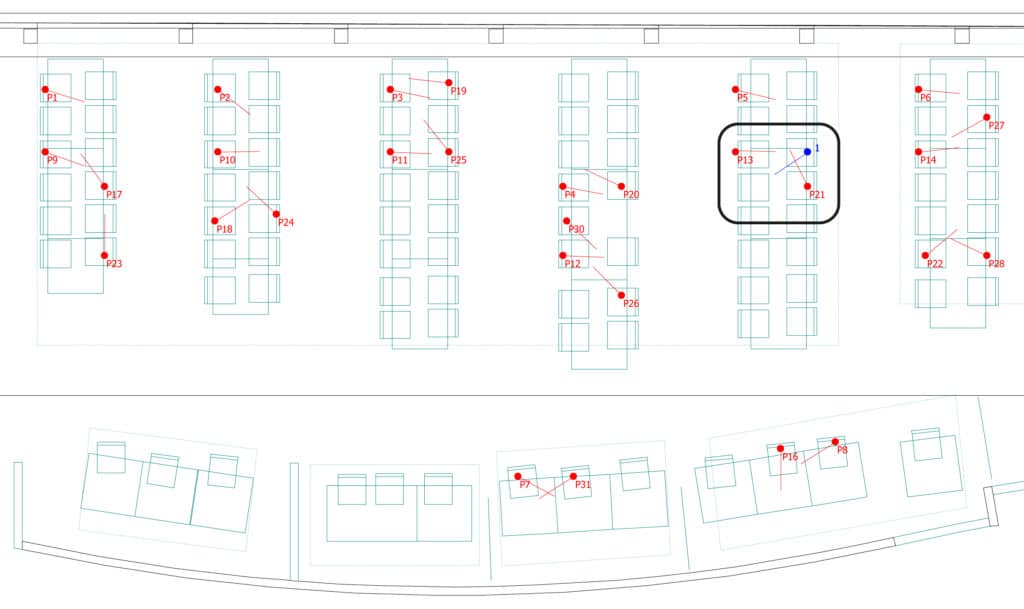
Detail of the cafeteria with 31 sources and one receiver. Two simulations are examined with one of the sources (P13 and P21) next to the receiver, treated as the speech in focus. Source P13 is gradually placed closer to the receiver, following the distances 1.0m, 0.75m and 0.5m.